Securing Outbound Connectivity — Using Managed Private Endpoints from Fabric Spark
This blog post explains how to use managed private endpoints in Fabric to securely access different Azure resources from Fabric Spark.
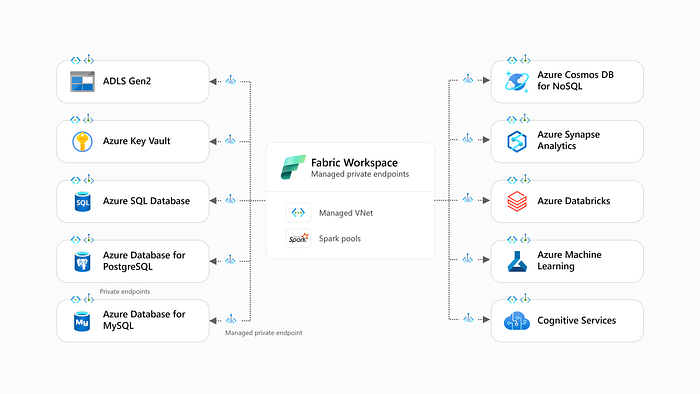
This blog is divided into two parts:
1. Setting up the basics: provides an example of deploying Azure resources with private endpoints using Terraform and explains how to create managed private endpoints from Fabric and approve them on Azure.
∟ Deploying secure Azure resources with Terraform
∟ Creating manage private endpoints on Fabric
2. Connecting to secure Azure resources: provides examples of connecting to secure Azure resources from Fabric Spark. For direct access to specific examples, use the links below.
∟ ADLS Gen2
∟ Azure Key Vault
∟ Azure SQL Database
∟ Azure Database for PostgreSQL
∟ Azure Database for MySQL
∟ Azure Cosmos DB for NoSQL
∟ Azure Synapse Analytics (serverless and dedicated)
∟ Azure Databricks
∟ Azure Machine Learning
∟ Cognitive Services
Setting up the basics
Deploying secure Azure resources
Before configuring managed private endpoints for Azure resources in Fabric, ensure you’ve deployed Azure resources with private endpoints. For guidance, visit this GitHub repository to deploy the above-listed Azure resources using Terraform, including the necessary private endpoints.
Prerequisites:
- An Azure subscription
- The Terraform CLI installed
- Git installed
Deploying the infrastructure:
Execute the commands below to deploy the required infrastructure:
# Initialize the Terraform configuration by running
terraform init
# Then, apply the configuration using
terraform apply -auto-approve
Creating managed private endpoints on Fabric
Once resources are deployed, to establish a secure connection to an Azure resource, follow these steps within your Fabric workspace:
Create a managed private endpoint:
- Enter the resource identifier: for instance, for ADLS Gen2
/subscriptions/<subcription_id>/resourceGroups/<resource_group>/providers/Microsoft.Storage/storageAccounts/<storage_account> - Select the target sub-resource: for instance, to create a private endpoint to dfs, use “Azure Data Lake Storage Gen2”.
Approve the private endpoint connection:
- Once the connection is established, go the the appropiate resource in the Azure portal and approve the private endpoint connection coming from Fabric. Alternatively, use Azure CLI for approval.
Note: repeat this process for each managed private endpoint you wish to create for an Azure resource.
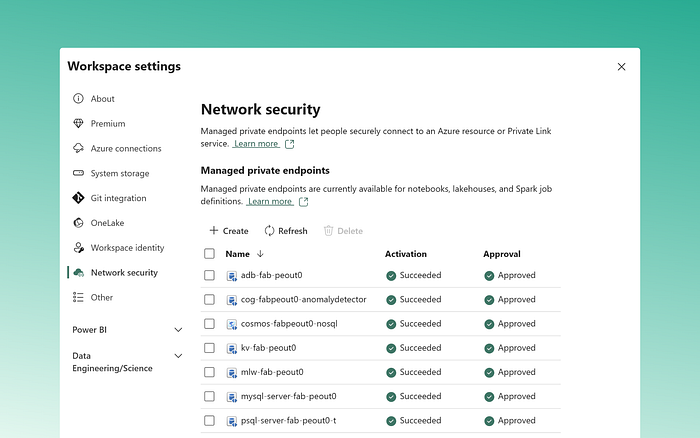
Connecting to secure data sources
ADLS Gen2
Storage accounts supports five different private endpoints. In this case, create a managed private endpoints using the privatelink.dfs.core.window.net private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.Storage/storageAccounts/
<storage_account>
∟ Target sub-resource: Azure Data Lake Storage Gen2Test access
Once the managed private endpoint is successfully deployed and approved, you can securely access ADLS Gen2, for example, using Service Principal (SPN) authentication. Grant the SPN RBAC access (e.g. Storage Blog Data Contributor) on ADLS Gen2.
Note: see different ways of accessing ADLS Gen2 from Fabric Spark
# spn
storage_account = "<storage_account>"
tenant_id = "<tenant_id>"
service_principal_id = "<service_principal_id>"
service_principal_password = "<service_principal_password>"
spark.conf.set(f"fs.azure.account.auth.type.{storage_account}.dfs.core.windows.net", "OAuth")
spark.conf.set(f"fs.azure.account.oauth.provider.type.{storage_account}.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set(f"fs.azure.account.oauth2.client.id.{storage_account}.dfs.core.windows.net", service_principal_id)
spark.conf.set(f"fs.azure.account.oauth2.client.secret.{storage_account}.dfs.core.windows.net", service_principal_password)
spark.conf.set(f"fs.azure.account.oauth2.client.endpoint.{storage_account}.dfs.core.windows.net", f"https://login.microsoftonline.com/{tenant_id}/oauth2/token")
df = spark.read.format("csv").option("header", "true").load(f"abfss://default@{storage_account}.dfs.core.windows.net/employees.csv")
df.show(10)Azure Key Vault
For Azure Key Vault, create a managed private endpoint using privatelink.vaultcore.azure.net private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.KeyVault/vaults/<key_vault>
∟ Target sub-resource: Azure Key VaultTest access
With the managed private endpoint enabled, you can now retrieve a secret from Key Vault e.g. using user identity or SPN authentication. Grant the UPN or SPN secret retrieval permissions on the Key Vault.
kv_uri = "https://kv-fab-peout0.vault.azure.net/"
secret_name = "testsecret"
# upn
mssparkutils.credentials.getSecret(kv_uri, secret_name)
# upn with TL
from trident_token_library_wrapper import PyTridentTokenLibrary as tl
access_token = mssparkutils.credentials.getToken("keyvault")
tl.get_secret_with_token(kv_uri, secret_name, access_token)
# spn
from azure.identity import ClientSecretCredential
from azure.keyvault.secrets import SecretClient
credentials = ClientSecretCredential(client_id=service_principal_id, client_secret=service_principal_password,tenant_id=tenant_id)
client = SecretClient(vault_url = kv_uri, credential = credentials)
get_secret = client.get_secret(secret_name).value
print(get_secret)Azure SQL Database
For Azure SQL Database, create a managed private endpoint using privatelink.database.windows.net private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.Sql/servers/<azure-sql-server>
∟ Target sub-resource: Azure SQL DatabaseTest access
With the managed private endpoint enabled, you can query a table from the Azure SQL database, e.g. using username and password authentication.
server_name = "<server_name>"
database = "<database>"
port = 1433
username = "<username>"
password = "<password>"
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("TestSecureAzureSQLDB") \
.config("spark.jars.packages", "com.microsoft.azure:azure-sqldb-spark:1.0.2").getOrCreate()
# username and password
jdbc_url = f"jdbc:sqlserver://{server_name}:{port};database={database}"
connection = {"user":username,"password":password,"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"}
df = spark.read.jdbc(url=jdbc_url, table = "dbo.Student", properties=connection)
df.show(10)Azure Database for PostgreSQL
Create a managed private endpoint for the Azure PostgreSQL database using the privatelink.postgres.database.azure.com private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.DBforPostgreSQL/servers/<psql-server>
∟ Target sub-resource: Azure Database for PostgreSQLTest access
With the managed private endpoint enabled, you can query a table from the Azure PostgreSQL database, e.g. using username and password authentication.
server_name = "<server_name>"
database = "<database>"
port = 5432
username = "<username>"
password = "<password>"
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("TestSecurePsql") \
.config("spark.jars.packages", "org.postgresql:postgresql:42.2.9").getOrCreate()
# username and password
jdbc_url = f"jdbc:postgresql://{server_name}:{port}/{database}"
connection = {"user":username,"password":password,"driver": "org.postgresql.Driver"}
df = spark.read.jdbc(url=jdbc_url, table = "Course", properties=connection)
df.show(10)Azure Database for MySQL
Create a managed private endpoint for the Azure MySQL database using the privatelink.mysql.database.azure.com private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.DBforMySQL/servers/<mysql-server>
∟ Target sub-resource: Azure Database for MySQLTest access
With the managed private endpoint enabled, you can query a table from the Azure MySQL database, e.g., using username and password authentication.
database = "<database>"
port = 3302
username = "<username>"
password = "<password>"
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("TestSecureMySQL") \
.config("spark.jars", "mysql-connector-java-8.0.18").getOrCreate()
jdbc_url = f"jdbc:mysql://{server_name}:{port}/{database}?enabledTLSProtocols=TLSv1.2&useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC"
connection = {"user":dbUserName,"password":dbPassword,"driver": "com.mysql.cj.jdbc.Driver"}
df = spark.read.jdbc(url=jdbc_url, table = "Course", properties=connection)
df.show(10)Azure Cosmos DB for NoSQL
Create a managed private endpoint for the Azure CosmosDB NoSQL database using the privatelink.documents.azure.com private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.DocumentDB/databaseAccounts/<cosmos>
∟ Target sub-resource: Azure Cosmos DB for NoSQLTest access
With the managed private endpoint enabled, you can query a CosmosDB container, e.g. using the account endpoint and key.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("TestSecureCosmosNoSQL") \
.config("spark.jars.packages", "com.microsoft.azure:cosmos-analytics-spark-3.4.1-connector_2.12:1.8.10").getOrCreate()
config = {
"spark.cosmos.accountEndpoint": "<account_endpoint>",
"spark.cosmos.accountKey": "<account_key>",
"spark.cosmos.database": "<database>",
"spark.cosmos.container": "<container>"
}
# with account key
df = spark.read.format("cosmos.oltp") \
.options(**config) \
.option("spark.cosmos.read.inferSchema.enabled", "true") \
.load()
df.show(10)Azure Synapse Analytics
To connect to Azure Synapse securely, you need to create three different private DNS zones. See how to deploy a secure Azure Synapse workspace using Terraform.
To read data from serverless and dedicated SQL pools, create two managed private endpoints using the privatelink.sql.azuresynapse.net private DNS zone.
# serverless
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.Synapse/workspaces/<syn-workspace>
∟ Target sub-resource: Azure Synapse Analytics (SQL On Demand)
# dedicated pools
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.Synapse/workspaces/<syn-workspace>
∟ Target sub-resource: Azure Synapse Analytics (SQL)Test access
With both managed private endpoints enabled, you can query serverless and dedicated SQL pools using e.g., SQL authentication.
# serverless
server_name = "<name>-ondemand.sql.azuresynapse.net"
database = "<database>"
port = 1433
username = "<username>"
password = "<password>"
jdbc_url = f"jdbc:sqlserver://{server_name}:{port};database={database};user={username};password={password};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;"
df = spark.read.jdbc(url=jdbc_url, table = "populationExternalTable")
df.show(10)
# dedicated pools
server_name = "<name>.sql.azuresynapse.net"
database = "<database>"
port = 1433
username = "<username>"
password = "<password>"
jdbc_url = f"jdbc:sqlserver://{server_name}:{port};database={database};user={username};password={password};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;"
df = spark.read.jdbc(url=jdbc_url, table = "Course")
df.show(10)Azure Databricks
Create a managed private endpoint for the Azure Databricks workspace using the privatelink.azuredatabricks.net private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.Databricks/workspaces/<dbx-workspace>
∟ Target sub-resource: Azure DatabricksTest access
With managed private endpoint enabled, you can connect to Azure Databricks using JDBC or ODBC drivers. Here’s a simple example using the JDBC driver with PAT token authentication. Explore different authentication methods here.
Note: configure the Fabric Spark session with com.databricks:databricks-jdbc:2.6.36 jar.
server_name = "<server_name>"
http_path = "<http_path>"
pat_token = "<pat_token>"
jdbc_url = f"jdbc:databricks://{server_name}:443;httpPath={http_path};AuthMech=3;UID=token;PWD={pat_token}"
table_name = "<table_name>"
df = spark.read.format("jdbc").option("url", jdbc_url).option("dbtable", table_name).option("driver", "com.databricks.client.jdbc.Driver").load()
df.show(10)Azure Machine Learning
A secure Azure Machine Learning (AML) workspace includes a container registry, a storage account (without hierarchical namespaces), a Key Vault, and an application insights instance, each with corresponding private endpoints where applicable.
To securely connect to an AML workspace, create a managed private endpoint using the privatelink.api.azureml.ms private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.MachineLearningServices/workspaces/
<mlw-workspace>
∟ Target sub-resource: Azure Machine LearningTest access
With the managed private endpoint enabled, you can test AML workspace connectivity or use AML model uri for score prediction, for instance.
from azureml.core import Workspace
from azureml.core.authentication import ServicePrincipalAuthentication
tenant_id = "<tenant_id>"
service_principal_id = "<service_principal_id>"
service_principal_password = "<service_principal_password>"
aml_subscription_id = "<aml_subscription_id>"
aml_resource_group = "<aml_resource_group>"
aml_workspace_name = "<aml_workspace_name>"
svc_pr = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=service_principal_id,
service_principal_password=service_principal_password
)
ws = Workspace(
workspace_name = aml_workspace_name,
subscription_id = aml_subscription_id,
resource_group = aml_resource_group,
auth=svc_pr
)
ws.get_details()Azure Cognitive Services
Create a managed private endpoint for the Azure Cognitive Service account using the privatelink.cognitiveservices.azure.com private DNS zone.
∟ Resource identifier: /subscriptions/<subcription_id>/resourceGroups/
<resource_group>/providers/Microsoft.CognitiveServices/accounts/<cog-name>
∟ Target sub-resource: Cognitive ServicesTest access
With the managed private endpoint enabled, this simple example shows how to use the anomaly detector API based on the data existing in the lakehouse.
import requests
subscription_key = "<subscription_key>"
api_endpoint = "<api_endpoint>"
anomaly_detector_url = f'{api_endpoint}/anomalydetector/v1.0/timeseries/last/detect'
headers = {
'Ocp-Apim-Subscription-Key': subscription_key,
'Content-Type': 'application/json'
}
data = load_json_from_path("/lakehouse/default/Files/test-ts-data.json")
response = requests.post(anomaly_detector_url, headers=headers, json=data)
if response.status_code == 200:
print(response.json())
else:
print(f'Error: {response.status_code}, {response.text}')Conclusions
In this blog, we’ve explored connecting to various secured Azure resources from Fabric Spark using managed private endpoints. This ensures a Microsoft backbone secure connection, enhancing data privacy and compliance.
The Azure resource list presented in this blog is not exhaustive; you can also create managed private endpoints for additional sources. However, consider existing limitations and considerations:
- Starter pools limitations: Workspaces with managed virtual networks (VNets) can’t access starter pools, even after removing the managed private endpoints. Fix coming soon.
- SKUs: (update) managed private endpoinsts are now available in all F capacities Fabric September 2024 Monthly Update | Microsoft Fabric Blog | Microsoft Fabric.
- Data sources: See the list of all supported private endpoints here.
- Cross-tenant: You can create cross-tenant managed private endpoints. Example: having a Key Vault in tenantA, and creating a managed private endpoint from Fabric tenantB.
- Table maintenance operations: VACUUM and OPTIMIZE operations from the lakehouse are not supported yet when using managed private endpoints. Fix coming soon.
- Num. of managed private endpoints: the number of managed private endpoints you can create is tied to the limit set at the data source level. For instance, maximum number of private endpoints per storage account is set to 200 by default.
Thanks Santhosh for his contributions and review.
References:
- Overview of managed virtual networks in Microsoft Fabric (preview) — Microsoft Fabric | Microsoft Learn
- Databricks and Fabric — writing to OneLake and ADLS Gen2 | by Aitor Murguzur | Feb, 2024 | Medium
- Creating Managed and External Spark Tables in Fabric Lakehouse | by Aitor Murguzur | Medium
- Azure/azure-data-labs-modules: A list of Terraform modules to build your Azure Data IaC templates. (github.com)